はじめに
座標とラベルが与えられた配列が与えられ、ラベル別に色分けされた図を描画したいとき、どうすれば良いだろうか。
機械学習の勉強をしていて、pandasを使ってラベル別に色分けして描画する方法を紹介している記事はいくつかあった。しかし、リストやnumpy配列に関して、色分けされた散布図を書く方法は解説されていなかった。そこで、あらゆる場面に対応した、汎用的な関数を作ることにした。
ラベル別に点の座標群を格納するための関数
対象とするデータは、例えば次のようなデータである。X_trainには6の要素が含まれ、二次元座標における6つの座標を表している。これを描画する際に、ラベルごとにX_trainの要素を分けたいと考える。
X_train = np.array([[23.5,44.0],[24.0,40.5],[26.0,25.5],[26.5,42.5],[28.0,50.5],[30.0,43.0]])# 座標
y = ["good","good","good","good","bad","bad"] # ラベル上の場合は、スライスを使ってデータ数を4対2に分ければよさそうである。しかし、次のような場合はそう簡単にはいかない。5番目の要素が、3番目の要素に移動しただけなのだが、もうスライスでは対応できない。6つのデータなら手作業で対応できそうだが、何10何100それ以上とデータが増えれば、手作業でラベルごとにデータを並べるのは現実的ではない。
X_train = np.array([[23.5,44.0],[24.0,40.5],[28.0,50.5],[26.0,25.5],[26.5,42.5],[30.0,43.0]])# 座標
y = ["good","good","bad","good","good","bad"] # ラベルそこで、以下のような関数を作成した。辞書型を使ってラベル別にデータを分けるための関数である。
# ラベル別に点の座標群を格納するための関数
def group(X, labels):
groups = {}
u, index = np.unique(labels, return_inverse=True)
for i in u:
# ユニークなラベルiに一致するインデックスを取得
# https://algorithm.joho.info/programming/python/list-indexes/
members_idx = [j for j, e in enumerate(labels) if e == i]
groups[i] = X[members_idx]
return groups作った関数を元に、ラベルごとに色分けされた散布図を書いてみる
import numpy as np
import matplotlib.pyplot as plt
# ラベル別に点の座標群を格納するための関数
def group(X, labels):
groups = {}
u, index = np.unique(labels, return_inverse=True)
for i in u:
# ユニークなラベルiに一致するインデックスを取得
# https://algorithm.joho.info/programming/python/list-indexes/
members_idx = [j for j, e in enumerate(labels) if e == i]
groups[i] = X[members_idx]
print(groups)
return groups
# サンプルの生成
x1 = np.random.rand(10)
y1 = np.random.rand(10)
X1 = np.array([[x,y,"good"] for x,y in zip(x1,y1)])
x2 = -np.random.rand(10)
y2 = -np.random.rand(10)
X2 = np.array([[x,y,"bad"] for x,y in zip(x2,y2)])
sample = np.concatenate([X1, X2])
np.random.shuffle(sample)
X = sample[:, :2]
labels = sample[:, 2]
# グラフの描画
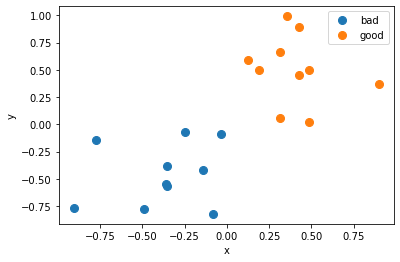
fig, ax = plt.subplots()
for key, value in group(X, labels).items():
print(key, value.astype(float))
ax.plot(value[:, 0].astype(float) , value[:, 1].astype(float), marker='o', linestyle='', ms=8, label=key)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend()
plt.show()何をやっているのかわかりにくいかもしれないが、まず、元のデータが下のようになっている。
print(X)
>> [['0.7145934583209103' '0.39661377438393863']
['0.2755624329525467' '0.7879762254795237']
['-0.0366751459968111' '-0.44808672566071905']
['0.12521096799606102' '0.34651747281884115']
['-0.713828919324073' '-0.2285487208678787']
['0.8328335871576944' '0.35389884591206644']
['0.6811658617516048' '0.7977466597689811']
['-0.8334184289218328' '-0.011164407607416882']
['-0.6618253262599072' '-0.20802147057952647']
['-0.08621001183204724' '-0.606194735254071']
['0.4813100279550667' '0.2736434299952971']
['0.025865733512404843' '0.4429894860921816']
['0.31533135558866476' '0.26366692352151244']
['0.4915841981080463' '0.3496173779708879']
['-0.5474744527297492' '-0.02332353147643096']
['-0.8091703010792731' '-0.6764711550018949']
['-0.23200010187306208' '-0.38021347541695794']
['-0.6904654313790407' '-0.5637176867624852']
['-0.4309963855824901' '-0.14941463201612393']
['0.13956719556961605' '0.5631051262125302']]
print(labels)
>> ['good' 'good' 'bad' 'good' 'bad' 'good' 'good' 'bad' 'bad' 'bad' 'good'
'good' 'good' 'good' 'bad' 'bad' 'bad' 'bad' 'bad' 'good']そして、group(X, labels)によってラベルごとにデータを分けてくれる。
group(X, labels)
>> {'bad': array([['-0.0366751459968111', '-0.44808672566071905'],
['-0.713828919324073', '-0.2285487208678787'],
['-0.8334184289218328', '-0.011164407607416882'],
['-0.6618253262599072', '-0.20802147057952647'],
['-0.08621001183204724', '-0.606194735254071'],
['-0.5474744527297492', '-0.02332353147643096'],
['-0.8091703010792731', '-0.6764711550018949'],
['-0.23200010187306208', '-0.38021347541695794'],
['-0.6904654313790407', '-0.5637176867624852'],
['-0.4309963855824901', '-0.14941463201612393']], dtype='<U32'),
'good': array([['0.7145934583209103', '0.39661377438393863'],
['0.2755624329525467', '0.7879762254795237'],
['0.12521096799606102', '0.34651747281884115'],
['0.8328335871576944', '0.35389884591206644'],
['0.6811658617516048', '0.7977466597689811'],
['0.4813100279550667', '0.2736434299952971'],
['0.025865733512404843', '0.4429894860921816'],
['0.31533135558866476', '0.26366692352151244'],
['0.4915841981080463', '0.3496173779708879'],
['0.13956719556961605', '0.5631051262125302']], dtype='<U32')}そして、最終的に、ラベルごとに色分けされた散布図を描画することができる。
まとめ
いかがだっただろうか。pandasでは表形式のデータのグルーピングなどは得意であるが、単純な配列を使ってグラフを書く機会もあるだろう。その際、本記事で紹介した関数が役に立てばと思う。
また、途中で数値データが文字列化してしまうのが難点だったため、numpyのarg何とかの関数を使って、もっとスマートな再配列の仕方がないか勉強したい。

コメント